Module 4: Topic Modeling
Module Overview
Topic Modeling is an unsupervised machine learning technique that automatically identifies topics present in text and derives hidden patterns in a corpus of documents. In this module, we'll explore Latent Dirichlet Allocation (LDA), a popular topic modeling algorithm, and learn how to implement it using the Gensim library. We'll also cover how to interpret the results of topic models and extract meaningful insights from document collections. These techniques are crucial for organizing, searching, and understanding large volumes of unstructured text data.
Learning Objectives
- Describe the Latent Dirichlet Allocation Process
- Implement a Topic Model using the Gensim library
- Interpret Document Topic Distributions and summarize findings from a topic model
Objective 01 - Describe the Latent Dirichlet Allocation Process
Overview
In the previous module, we did some basic document classification using latent semantic analysis (LSA). With that method, we found common "concepts" in documents and compared them to other documents to find similarities. In this next module, we will go deeper into learning more about topics in our documents.
Topics
First, let's define what a topic is. A text about a specific topic, like astronomy or cats, or cooking: we would expect to find similar words in any documents about the same topic. Articles and books about astronomy would include terms like "planet," "orbit," and "telescope." A text about cooking would have different words; for example, "mixing," "oven," and "diced" are standard terms used in cooking. But, these documents on two different topics would also have words in common, such as "temperature," "scale," and "measure."
So how do we determine which "topics" are in a document? Math! We can use various mathematical and statistical techniques to determine these topics and their representation in a text. This module will focus on a technique called latent Dirichlet allocation (LDA).
Latent Dirichlet allocation
The basis of the LDA model is that it assumes that a document is a mixture of topics and that all the words in the document (after removing stop words and stemming/lemmatization) belong to a topic. A more straightforward way might be to say each document is a mixture of topics and each topic is a mixture of words.
More generally, LDA is an unsupervised learning (clustering) technique, where the clusters are the topics. You can also think about representing a document in "topic space" in the same way that we use word embeddings to describe a word in a vector space.
One of the parameters to specify when fitting an LDA model is the number of topics. Unfortunately, the parameter isn't something that can be measured or determined before actually assigning words to topics. But, we can optimize the number of topics by measuring the performance during a classification or regression task by determining how many different topics there are.
In the next objective, we'll dive into creating topic models with some Python packages. But for now, we'll look at the simple topics for a small collection of documents. By this, we mean five sentences! So first, let's find some topics.
Follow Along
Let's pretend we want to find the topics in this corpus:
- "Many people have believed that the summer season is hot because the Earth is closer to the Sun."
- "Would the state of liquid water change to a solid or gas on the surface of the Moon?"
- "After discussing their problems, the underlying issue began to surface."
- "The recipe did state specific cooking directions but didn't indicate how to season the food."
- "The state needs to issue the document."
Some words have multiple meanings, such as season (time of year or food flavoring), state (form of matter or geographic location), and issue (to give out or problem/difficulty).
What topics can we identify in these documents? First, we have statements related to science topics (Earth, Sun, state of liquid) and other sentences that refer to more general topics like cooking or paperwork.
Let's see what topics we produce if we fit an LDA model to this text. First, we have to choose the number of topics, so we'll select a small number of topics like three for a small sample like this. Then for each topic, we'll look at the top three words. There are more than nine words (3*3) in our corpus, but for now, three should be enough to get an idea of what the topic is.
Don't worry about the details of fitting the model right now; we'll get to this in the next objective.
Topics
| topic | word1 | word2 | word3 |
|---|---|---|---|
| 0 | state | water | liquid |
| 1 | season | people | believed |
| 2 | issue | surface | underlying |
We have our three topics and the words associated with those topics. The first topic seems like it can be called "science" since state seems to be associated with the scientific definition. The second topic is more challenging to classify, but "season" seems to be associated with things people do rather than the weather. And the last topic could be called "psychology," as it seems those are terms a counselor might use.
Even with this small example, we're starting to feel what a topic is, especially when we can easily see and read the whole corpus. Usually, we'll deal with large amounts of text.
Challenge
Using the topic modeling application available at this website, try adding some of you own documents. Suggestions for what to use here include:
- A paragraph of text from an open source text book or non-fiction article (NASA, science news letters, etc.)
- Excerpts from novels by different authors from public domain texts on Project Gutenberg
- A sample of your own writing on a topic compared to a sample from a different source
Additional Resources
Objective 02 - Implement a Topic Model Using the Gensim Library
Overview
In the last objective, we looked at a small corpus of five sentence-length documents and used latent Dirichlet allocation (LDA) to find the topics in that corpus. In this next part, we will demonstrate how to use the gensim Python package to do some topic modeling using LDA.
We'll go through the following steps to find the topics; the text we'll use is "Alice in Wonderland" by Lewis Carroll. The text was prepared by selecting paragraph-sized chunks of text from the book. In the analysis, each chunk of text will be considered a document.
Topic Modeling Steps
- Prepare text: Load text file, split into documents, tokenize/lemmatize, remove stop words
- Create the term dictionary for the corpus
- Create a document term matrix (DTM)
- Set up the LDA model, decide on the number of topics
- Run and train the model
- Topics!
Follow Along
The "Alice in Wonderland" text was downloaded from the Gutenberg Project. The file used in this analysis can be found here.
# Imports
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
# Add additional stop words
#STOPWORDS = set(STOPWORDS).union(set(['said', 'mr', 'mrs']))
# Function for tokenizing the
def tokenize(text):
return [token for token in simple_preprocess(text) if token not in STOPWORDS]
# Read in the text (download to run locally)
with open('wonderland.txt', 'r') as file:
text_str = file.read()
# Split the string on the newline character
text = text_str.split('\n')
# Tokenize each chunk of text
text_tokens = [tokenize(chunk) for chunk in text]
# Look at the first 10 tokens
text_tokens[0][0:10]
['alice',
'beginning',
'tired',
'sitting',
'sister',
'bank',
'having',
'twice',
'peeped',
'book']
# Imports
from gensim import corpora
# Create the term dictionary of our corpus
# every unique term is assigned an index
dictionary = corpora.Dictionary(text_tokens)
# Convert list of documents (corpus) into Document Term Matrix
# using the dictionary we just created
doc_term_matrix = [dictionary.doc2bow(doc) for doc in text_tokens]
# What does this matrix look like?
print(doc_term_matrix[0][0:25])
[(0, 1), (1, 4), (2, 1), (3, 1), (4, 2), (5, 1), (6, 1), (7, 1), (8, 1), (9, 2), (10, 1), (11, 1), (12, 1), (13, 1), (14, 2), (15, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1), (22, 1), (23, 1), (24, 1)]
The document term matrix consists of an ID for each unique term in the document and how many times that term appears. So, for example, in the section we printed above, we're looking at the first 25 terms in the first document.
Now let's use this document term matrix to train our LDA model. We need to set the number of topics ahead of time; let's choose five.
# Imports
from gensim.models.ldamulticore import LdaMulticore
# Create the object for LDA model
lda = gensim.models.ldamodel.LdaModel
# Train LDA model on the document term matrix
# topics = 5
ldamodel = lda(doc_term_matrix, num_topics=5, id2word = dictionary, passes=50)
# Print out the topics
print(ldamodel.print_topics(num_topics=3, num_words=5))
[(1, '0.029*"turtle" + 0.024*"said" + 0.024*"mock" + 0.020*"gryphon" + 0.015*"alice"'), (0, '0.027*"rabbit" + 0.020*"alice" + 0.014*"white" + 0.014*"time" + 0.014*"dear"'), (2, '0.025*"little" + 0.020*"alice" + 0.009*"ran" + 0.009*"looking" + 0.009*"head"')]
These topics look good but it might be easier to look at them in a more readable format.
import re
words = [re.findall(r'"([^"]*)"', t[1]) for t in ldamodel.print_topics()]
topics = [' '.join(t[0:5]) for t in words]
for id, t in enumerate(topics):
print(f"------ Topic {id} ------")
print(t, end="\n\n")
------ Topic 0 ------
rabbit alice white time dear
------ Topic 1 ------
turtle said mock gryphon alice
------ Topic 2 ------
little alice ran looking head
------ Topic 3 ------
came hearts said alice procession
------ Topic 4 ------
king alice executioner queen look
When we do topic modeling, the topics don't always make sense as human readers. But these topics are somewhat readable, and we might even assign "themes" to these topics. So in the next objective, we're going to look at how to interpret these topics.
Challenge
Following the example above, try to change the number of topics and the number of words displayed per topics. How do the topics change? Do they make more sense if we can group them into more topic clusters? Does it help to view more words per topic?
Additional Resources
Objective 03 - Interpret Document Topic Distributions and Summarize Findings
Overview
When we interpret topics, we need to understand how the words are being used in the documents and their meaning in that context. We also want to look at how the topics relate to each other and the distribution of words.
For the small example here, the topics might make a lot of sense, and we aren't comparing them to
novels by other authors. But we can make use of the pyLDAvis library to explore our
topic model.
Follow Along
We will load the same "Alice in Wonderland" text from the last objective and run an LDA model with
five topics. After creating our model, we'll use the pyLDAvis library to produce an
interactive visualization of our topics.
# Suppress annoying warning
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
# Import the library
import pyLDAvis.gensim
# Use the visualization in a notebook
pyLDAvis.enable_notebook()
# Repeat the topic model from the previous objective
# Imports
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
# Add additional stop words
#STOPWORDS = set(STOPWORDS).union(set(['said', 'mr', 'mrs']))
# Function for tokenizing the
def tokenize(text):
return [token for token in simple_preprocess(text) if token not in STOPWORDS]
# Read in the text (download to run locally)
with open('wonderland.txt', 'r') as file:
text_str = file.read()
# Split the string on the newline character
text = text_str.split('\n')
# Tokenize each chunk of text
text_tokens = [tokenize(chunk) for chunk in text]
# Imports
from gensim import corpora
# Create the term dictionary of our corpus
# every unique term is assigned an index
dictionary = corpora.Dictionary(text_tokens)
# Convert list of documents (corpus) into Document Term Matrix
# using the dictionary we just created
doc_term_matrix = [dictionary.doc2bow(doc) for doc in text_tokens]
# Imports
from gensim.models.ldamulticore import LdaMulticore
# Create the object for LDA model
lda = gensim.models.ldamodel.LdaModel
# Train LDA model on the document term matrix
# topics = 5
ldamodel = lda(doc_term_matrix, num_topics=5, id2word = dictionary, passes=50)
# Interactive visualization for topic modeling
# Uncomment the following line to start the interactive visualization
# (a screenshot will be displayed below)
#pyLDAvis.gensim.prepare(ldamodel, doc_term_matrix, dictionary)
Because we're viewing this content on a static site and not in a notebook, we cannot run this interactive visualization. But, we can see that this tool allows us to compare the word distributions within each topic (bar chart on the right). We can also see if there is any overlap between topics (bubble chart on the left).
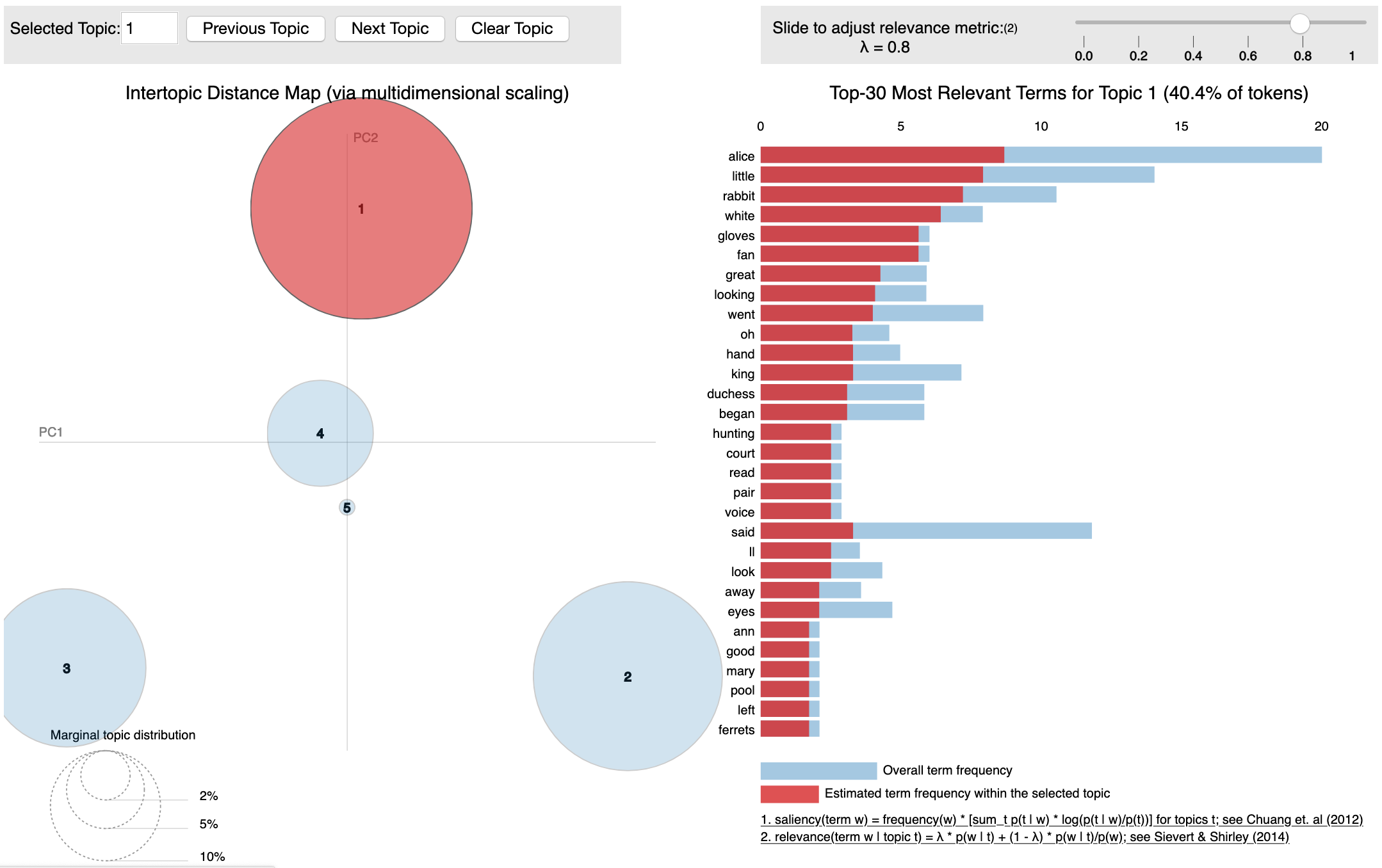
Challenge
Right now is an excellent time to try out pyLDAvis yourself! Using the same code and
the text available here, reproduce the above step to create
your topic model. You can even fit more topics and see how the distribution changes.
Additional Resources
Guided Project
Open DS_414_Topic_Modeling_Lecture_GP.ipynb in the GitHub repository to follow along with the guided project.
Note: The guided project solution notebook in the GitHub repository is currently broken.
Module Assignment
Apply topic modeling to analyze Amazon reviews using Gensim LDA. Clean the dataset, fit the model, select appropriate number of topics, and create visualizations to summarize your findings.